[I7R5]
Wen, Shi, Chen, and Liu (pp2017) used a deep residual neural network (trained on visual object classification) as an encoding model to explain human cortical fMRI responses to movies. The deep net together with the encoding weights of the cortical voxels was then used to predict human cortical response patterns to 64K object images from 80 categories. This prediction serves, not to validate the model, but to investigate how cortical patterns (as predicted by the model) reflect the categorical hierarchy.
The authors report that the predicted category-average response patterns fall into three clusters corresponding to natural superordinate categories: biological things, nonbiological things, and scenes. They argue that these superordinate categories characterize the large-scale organization of human visual cortex.
For each of the three superordinate categories, the authors then thresholded the average predicted activity pattern and investigated the representational geometry within the supra-threshold volume. They find that biological things elicit patterns (within the subvolume responsive to biological things) that fall into four subclusters: humans, terrestrial animals, aquatic animals, and plants. Patterns in regions activated by scenes clustered into artificial and natural scenes. The patterns in regions activated by non-biological things did not reveal clear subdivisions.
The authors argue that this shows that superordinate categories are represented in global patterns across higher visual cortex, and finer-grained categorical distinctions are represented in finer-grained patterns within regions responding to superordinate categories.
This is an original, technically sophisticated, and inspiring paper. However, the title claim is not compellingly supported by the evidence. The fact that finer grained distinctions become apparent in pattern correlation matrices after restricting the volume to voxels responsive to a given category is not evidence for an association between brain-spatial scales and conceptual scales. To understand this, consider the fact that the authors’ analyses do not take the spatial positions of the voxels (and thus the spatial structure) into account at all. The voxel coordinates could be randomly permuted and the analyses would give the same results.
The original global representational dissimilarity (or similarity) matrices likely contain distinctions not only at the superordinate level, but also at finer-grained levels (as previously shown). When pattern correlation is used, these divisions might not be prominent in the matrices because the component shared among all exemplars within a superordinate category dominates. Recomputing the pattern correlation matrix after reducing the patterns to voxels responding strongly to a given superordinate category will render the subdivisions within the superordinate categories more prominent. This results from the mean removal implicit to the pattern correlation, which will decorrelate patterns that share high responses on many of the included voxels. Such a result does not indicate that the subdivisions were not present (e.g. significantly decodable from fMRI or even clustered) in the global patterns.
A simple way to take spatial structure into account would be to restrict the analysis to a single spatially contiguous cluster at a time, e.g. FFA. This is in fact the approach taken in a large number of previous studies that investigated the representations in category-selective regions (LOC, FFA, PPA, RSC, etc.). Another way would be to spatially filter the patterns and investigate whether finer semantic distinctions are associated with finer spatial scales. This approach has also been used in previous studies, but can be confounded by the presence of an unknown pattern of voxel gains (Freeman et al. 2013; Alink et al. 2017, Scientific Reports).
The approach of creating a deep net model that explains the data and then analyzing the model instead of the data is a very interesting idea, but also raises some questions. Clearly we need deep nets with millions of parameters to understand visual processing. If a deep net explains visual responses throughout the visual system and shares at least some architectural similarities with the visual hierarchy, then it is reasonable to assume that it might capture aspects of the computational mechanism of vision. In a sense, we have “uploaded” aspects of the mechanism of vision into the model, whose workings we can more efficiently study. This is always subject to consideration of alternative models whose architecture might better match what is known about the primate visual system and which might predict visual responses even better. Despite this caveat, I believe that developing deep net models that explain visual responses and studying their computational mechanisms is a promising approach in general.
In the present context, however, the goal is to relate conceptual levels of categories to spatial scales of cortical response patterns, which can be directly measured. Is the deep net really needed to address this? To study how categories map onto cortex, why not just directly study measured response patterns? This is fact is what the existing literature has done for years. The deep net functions as a fancy interpolator that imputes data where we have none (response patterns for 64K images). However, the 80 category-average response patterns could have been directly measured. Would this not be more compelling? It would not require us to believe that the deep net is an accurate model.
Although the authors have gotten off to a fresh start on the intriguing questions of the spatial organization of higher-level visual cortex, the present results do not yet go significantly beyond what is known and the novel and interesting methods introduced in the paper (perhaps the major contribution) raise a number of questions that should be addressed in a revision.
Strengths
- Presents several novel and original ideas for the use of deep neural net models to understand the visual cortex.
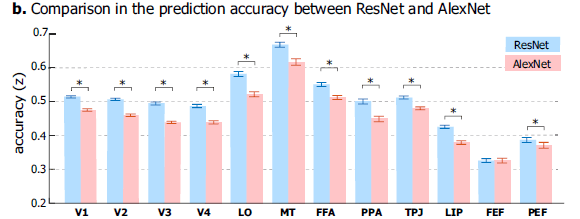
- Uses 50-layer ResNet model as encoding model and shows that this model performs better than the simpler AlexNet model.
- Tests deep net models trained on movie data for generalization to other movie data and prediction of responses in category-selective-region localizer experiments.
- Attempts to address the interesting hypothesis that larger scales of cortical organization serve to represent larger conceptual scales of categorical representation.
- The analyses are implemented at a high level of technical sophistication.
Weaknesses
- The central claim about spatial structure of cortical representations is not supported by evidence about the spatial structure. In fact, analyses are invariant to the spatial structure of the cortical response patterns.
- Unclear what added value is provided by the deep net for addressing the central claim that larger spatial scales in the brain are associated with larger conceptual scales.
- Uses a definition of “modularity” from network theory to analyze response pattern similarity structure, which will confuse cognitive scientists and cognitive neuroscientists to whom modularity is a computational and brain-spatial notion. Fails to resolve the ambiguities and confusions pervading the previous literature (“nested hierarchy”, “module”).
- Follows the practice in cognitive neuroscience of averaging response patterns elicited by exemplars of each category, although the deep net predicts response patterns for individual images. This creates ambiguity in the interpretation of the results.
- The central concepts modularity and semantic similarity are not properly defined, either conceptually or in terms of the mathematical formulae used to measure them.
- The BOLD fMRI measurements are low in resolution with isotropic voxels of 3.5 mm width.
Suggestions for improvements
(1) Analyze to what extent different spatial scales in cortex reflect information about different levels of categorization (or change the focus of the paper)
The ResNet encoding model is interesting from a number of perspectives, so the focus of the paper does not have to be on the association of spatial cortical and conceptual scales. If the paper is to make claims about this difficult, but important question, then analyses should explicitly target the spatial structure of cortical activity patterns.
The current analyses are invariant to where responses are located in cortex and thus fundamentally cannot address to what extent different categorical levels are represented at different spatial scales. While the ROIs (Figure 8a) show prominent spatial clustering, this doesn’t go beyond previous studies and doesn’t amount to showing a quantitative relationship.
The emergence of subdivisions within the regions driven by superordinate-category images could be entirely due to the normalization (mean removal) implicit to the pattern correlation. Similar subdivisions could exist in the complementary set of voxels unresponsive to the superordinate category, and/or in the global patterns.
Note that spatial filtering analyses might be interesting, but are also confounded by gain-field patterns across voxels. Previous studies have struggled to address this issue; see Alink et al. (2017, Scientific Reports) for a way to detect fine-grained pattern information not caused by a fine-grained voxel gain field.
(2) Analyze measured response patterns during movie or static-image presentation directly, or better motivate the use of the deep net for this purpose
The question how spatial scales in cortex relate to conceptual scales of categories could be addressed directly by measuring activity patterns elicited by different images (or categories) with fMRI. It would be possible, for instance, to measure average response patterns to the 80 categories. In fact previous studies have explored comparably large sets of images and categories.
Movie fMRI data could also be used to address the question of the spatial structure of visual response patterns (and how it relates to semantics), without the indirection of first training a deep net encoding model. For example, the frames of the movies could be labeled (by a human or a deep net) and measured response patterns could directly be analyzed in terms of their spatial structure.
This approach would circumvent the need to train a deep net model and would not require us to trust that the deep net correctly predicts response patterns to novel images. The authors do show that the deep net can predict patterns for novel images. However, these predictions are not perfect and they combine prior assumptions with measurements of response patterns. Why not drop the assumptions and base hypothesis tests directly on measured response patterns?
In case I am missing something and there is a compelling case for the approach of going through the deep net to address this question, please explain.
(3) Use clearer terminology
Module: The term module refers to a functional unit in cognitive science (Fodor) and to a spatially contiguous cortical region that corresponds to a functional unit in cognitive neuroscience (Kanwisher). In the present paper, the term is used in the sense of network theory. However it is applied not to a set of cortical sites on the basis of their spatial proximity or connectivity (which would be more consistent with the meaning of module in cognitive neuroscience), but to a set of response patterns on the basis of their similarity. A better term for this is clustering of response patterns in the multivariate response space.
Nested hierarchy: I suspect that by “nested” the authors mean that there are representations within the subregions responding to each of the superordinate categories and that by “hierarchy” they refer to the levels of spatial inclusion. However, the categorical hierarchy also corresponds to clusters and subclusters in response-pattern space, which could similarly be considered a “nested hierarchy”. Finally, the visual system is often characterized as a hierarchy (referring to the sequence of stages of ventral-stream processing). The paper is not sufficiently clear about these distinctions. In addition, terms like “nested hierarchy” have a seductive plausibility that belies their lack of clear definition and the lack of empirical evidence in favor of any particular definition. Either clearly define what does and does not constitute a “nested hierarchy” and provide compelling evidence in favor of it, or drop the concept.
(4) Define indices measuring “modularity” (i.e. response-pattern clustering) and semantic similarity
You cite papers on the Q index of modularity and the LCH semantic similarity index. These indices are central to the interpretation of the results, so the reader should not have to consult the literature to determine how they are mathematically defined.
(5) Clarify results on semantic similarity
The correlation between LCH semantic similarity and cortical pattern correlation is amazing (r=0.93). Of course this has a lot to do with the fact that LCH takes a few discrete values and cortical similarity was first averaged within each LCH value.
What is the correlation between cortical pattern similarity and semantic similarity…
- for each of the layers of ResNet before remixing to predict human fMRI responses?
- after remixing to predict human fMRI responses for each of a number of ROIs (V1-3, LOC, FFA, PPA)?
- for other, e.g. word-co-occurrence-based, semantic similarity measures (e.g. word2vec, latent semantic analysis)?
(6) Clarify the methods details
I didn’t understand all the methods details.
- How were the layer-wise visual feature sets defined? Was each layer refitted as an encoding model? Or were the weights from the overall encoding model used, but other layers omitted?
- I understand that the sub-divisions of the three superordinate categories were defined by k-means clustering and that the Q index (which is not defined in the paper) was used. How was the number k of clusters determined? Was k chosen to maximize the Q index?
- How were the category-associated cortical regions defined, i.e. how was the threshold chosen?
(7) Cite additional previous studies
Consider discussing the work of Lorraine Tyler’s lab on semantic representations and Thomas Carlson’s paper on semantic models for explaining similarity structure in visual cortex (Carlson et al. 2013, Journal of Cognitive Neuroscience).