[I8R8]
Yang, Song, Newsome, and Wang (pp2017) trained a rate-coded recurrent neural network with 256 hidden units to perform a variety of classical cognitive tasks. The tasks combine a number of component processes including evidence accumulation over time, multisensory integration, working memory, categorization, decision making, and flexible mapping from stimuli to responses. The tasks include:
- speeded response indicating the direction of the stimulus (stimulus-response mapping)
- speeded response indicating the opposite of the direction of the stimulus (flexible stimulus-response mapping)
- response indicating the direction of a stimulus after a delay during which the stimulus is not visible (working memory)
- decision indicating which of two noisy stimulus inputs is stronger (evidence accumulation)
- decision indicating which of two ranges of the stimulus variable the stimulus falls in (categorization)
The 20 distinct tasks result from combining in various ways the requirements of accumulating stimulus evidence from two sensory modalities, maintaining stimulus evidence in working memory during a delay, deciding which category the stimulus fell in, and flexible mapping to responses.
The tasks reduce cognition to its bare bones and the model abstracts from the real-world challenges of perception (pattern recognition) and motor control, so as to focus on the flexible linkage between perception and action that we call cognition. The input to the model includes a “fixation” signal, sensory stimuli varying along a single circular dimension, and an rule input, that specifies a task index.
The fixation signal is given through a special unit, whose activity corresponds to the presence of a fixation dot on the screen in front of a primate subject. The fixation signal accompanies the perceptual and maintenance phases of the task, and its disappearance indicates that the primate or model should respond. The sensory stimulus (“direction of stimulus from fixation”) is encoded in a set of direction-tuned units representing the circular dimension. Each of two sensory modalities is represented by such a set of units. The task rule is entered in one-hot format through a set of task units that receive the task index throughout performance of a task (no need to store the current task in working memory). The motor output is a “saccade direction” encoded, similarly to the stimulus, by a set of direction-tuned units.
Such tasks have long been used in nonhuman primate cell recording and human imaging studies, and also in rodent studies, in order to investigate how basic building blocks of cognition are implemented in the brain. This paper provides an important missing link between primate cognitive neurophysiology and rate-coded neural networks, which are known to scale to real-world artificial intelligence challenges.
Unsurprisingly, the authors find that the network learns to perform all 20 tasks after interleaved training on all of them. They then perform a number of well-motivated analyses to dissect the trained network and understand how it implements its cognitive feats.
An important question is whether particular units serve task-specific or task-general functions. One extreme hypothesis is that each task is implemented in a separate set of units. The opposite hypothesis is that all tasks employ all units. In order to address the degree of task-generality of the units, the authors measure the extent to which each unit conveys relevant information in each task. This is measured by the variance of a unit’s activity across different conditions within a task (termed the task variance). The authors find that the network learns to share some of the dynamic machinery it learns among different tasks.
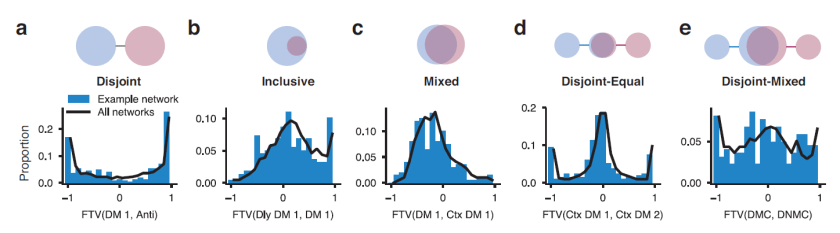
The authors find evidence for a compositional implementation of the tasks in the trained network. Compositionality here means that the tasks employ overlapping sets of functional components of the network. Rather than learning a separate dynamic systems for each task, the network appears to learn dynamic components serving different functions that can be flexibly combined to enable performance of a wide range of tasks.
The authors’ argument in favor of a compositional architecture is based on two observations: (1) Pairs of tasks that share cognitive component functions tend to involve overlapping sets of units. (2) Task-rule inputs, though trained in one-hot format, can be linearly combined (e.g. Delay Anti = Anti + Delay Go – Go) and the network given such a task specification (which it has never been trained on) will perform the implied task with high accuracy.
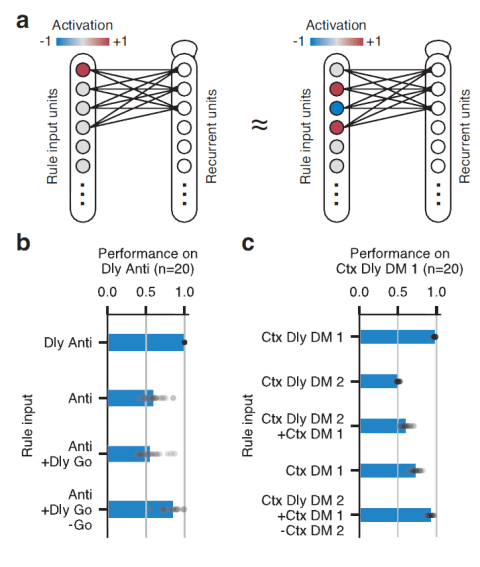
These analyses are interesting because they help us understand how the network works and because they can also be applied to primate cell recordings and help us compare models to brains.
When the network is sequentially trained on one task at a time, the learning of new tasks interferes with previously acquired tasks, reducing performance. However, a continual learning technique that selectively protects certain learned connections enabled sequential acquisition of multiple tasks.
Overall, this is a highly original paper presenting a simple, yet well-motivated model and several useful analysis methods for understanding biological and artificial neural networks. The model extends the authors’ previous work on the neural implementation of some of these components of cognition. Importantly, the paper helps strengthen the link between rate-coded neural network models and primate (and rodent) cognitive neuroscience.
Strengths
- The model is simple and well-designed and helps us imagine how basic components of cognition might be implemented in a recurrent neural network. It is essential that we build task-performing models to complement our fallible intuitions as to the signatures of cognitive processes we should expect in neuronal recordings.
- The paper links primate cognitive neurophysiology to rate-coded neural networks trained with stochastic gradient descent. This might help boost future interactions between neurophysiologists and engineers.
- The measures and analyses introduced to dissect the network are well-motivated, straightforward, and imaginative. Several of them can be equally applied to models and neuronal recordings.
- The paper is well-written, clear, and tells an interesting story.
- The figures are of high quality.
Weaknesses
- The tasks are so simple that they do not pose substantial computational challenges. This is a strength because it makes it easier to understand neuronal responses in primate brains and unit responses in models. We have to start from the simplest instances of cognition. However, it is also a weakness. Consider the comparison to understanding the visual system. One approach is to reduce vision to discriminating two predefined images. The optimal algorithm for this task is a linear filter applied to the image. The intuitive reduction of vision to this scenario supports the template-matching model. However, this task and its optimal solution fundamentally misconstrues the challenge of visual recognition in the real world, which has to deal with complex accidental variation within each category to be recognized. The dominant current vision model is provided by deep neural networks, which perform multiple stages of nonlinear transformation and learn rich knowledge about the world. Simple cognitive tasks provide a starting point, but – like the two-image discrimination task in vision – abstract away many essential features of cognition. In vision, models are tested in terms of their performance on never seen images – a generalization challenge at the heart of what vision is all about. In cognition as well, we ultimately have to engage complex tasks and test models in terms of their ability to generalize to new instances drawn randomly from a very complex space. The paper leaves me wondering how we can best take small steps from the simple tasks dominating the literature toward real-world cognitive challenges.
- The paper does not compare a variety of models. Can we learn about the mechanism the brain employs without comparing alternative models? Rate-coded recurrent neural networks are universal approximators of dynamical systems. This property is independent of particular choices defining the units. It is entirely unsurprising that such a model, trained with stochastic gradient descent, can learn these tasks (and the supertask of performing all 20 of them). Given the simplicity of the tasks, it is also not surprising that 256 recurrent units suffice. In fact, the authors report that the results are robust between 128 and 512 recurrent units. The value of this project consists in the way it extends our imagination and generates hypotheses (to be tested with neuronal recordings) about the distributions of task-specific and task-general units. The simplicity of the model and its gradient descent training provides a compelling starting point. However, there are infinite ways a recurrent neural network might implement performance at these tasks. It will be important to contrast alternative task-performing models and adjudicate between them with brain and behavioral data.
- The paper does not include analyses of biological recordings or behavioral data, which could help us understand the degree to which the model resembles or differs from the primate brain in the way it implements task performance.
Addressing all of these weaknesses could be considered beyond the scope of the current paper. But the authors should consider if they can go toward addressing some of them.
Suggested improvements
(1) It might be useful to explicitly model the 20 tasks in terms of cognitive component functions (multisensory integration, evidence accumulation, working memory, inversion of stimulus-response mapping, etc.). The resulting matrix could be added to Table 1 or shown separately. This compositional cognitive description of the tasks could be used to explain the patterns of unit involvement in different tasks (e.g. as measured by task variance) using a linear model. The compositional model could then be inferentially compared to a non-compositional model in which each task is has a single cognitive component function. This more hypothesis-driven approach might help to address the question of compositionality inferentially.
(2) The depiction of the neural network model in Figure 1 could give a better sense of the network complexity and architecture. Instead of the three-unit icon in the middle, how about a directed graph with 256 dots, one for each recurrent unit, and a separate circular arrangements of input and output units (how many were there?). Instead of the network-unit icon with the cartoon of the nonlinear activation, why not show the actual softplus function?
(3) It would the good to see the full 2562 connectivity matrix (ordered by clusters) and the network as a graph with nodes arranged by proximity in the connectivity matrix and edges colored to indicate the weights.
(4) The paper states that “the network can maintain information throughout a delay period of up to five seconds.” What does time in seconds mean in the context of the model? Is time meaningful because the units have time constants similar to biological neurons? It would be good to add supplementary text and perhaps a figure that explains how the pace of processing is matched to biological neural networks. If the pace is not compellingly matched, on the other hand, then perhaps real time units (e.g. seconds) should not be used when describing the model results.
(5) Please clarify whether the hidden units are fully recurrently connected. It would also be good to extend the paper to report how the density of recurrent connectivity affects task performance, learning, clustering and compositionality.
(6) The initial description of task variance is not entirely clear. State explicitly that one task variance estimate is computed for each task, reflecting the response variance across conditions within that task, and thus providing a measure of the stimulus-information conveyed during the task.
(7) Clustering is useful here as an exploratory and descriptive technique for dissecting the network, carving the model at its joints. However, clustering methods like k-means always output clusters, even when the data are drawn from a unimodal continuous distribution. The title claim of “clusters” thus should ideally be substantiated (by inferential comparison to a continuous model) or dropped.
(8) The clustering will depend on the multivariate signature used to characterize each unit. Instead of task variance patterns, a unit’s connectivity (incoming and outgoing) could be used as a signature and basis of clustering. How do results compare for this method? My guess is that using the task variance pattern across tasks tends to place units in the same cluster if they contribute to the same task, although they might represent different stimulus information in the task. If this is the motivation, it would be good to explain it more explicitly.
(9) It is an interesting question whether units in the same cluster serve the same function. (It seems unlikely in the present analyses, but would be more plausible if clustering were based on incoming and outgoing weights.) The hypothesis that units in a cluster serve the same function could be made precise by saying that the units in a cluster share the same patterns of incoming and outgoing connections, except for weight noise resulting from the experiential and internal noise during training. Under this hypothesis incoming weights are exchangeable among units within the same cluster. The same holds for outgoing weights. The hypothesis could, thus, be tested by shuffling the incoming and the outgoing weights within each cluster and observing performance. I would expect performance to drop after shuffling and would interpret this as a reminder that the cluster-level summary is problematic. Alternatively, to the extent that clusters do summarize the network well, one might try to compress the network down to one unit per cluster, by combining incoming and outgoing weights (with appropriate scaling), or by training a cluster-level network to approximate the dynamics of the original network.
(10) The method of t-SNE is powerful, but its results strongly depend on the parameter settings, creating an issue of researcher degrees of freedom. Moreover, the objective function is difficult to state precisely in a single sentence (if you disagree, please try). Multidimensional scaling by contrast uses a range of objective functions that are easy to define in a single sentence. I wonder why t-SNE should be preferred in this particular context.
(11) Another way to address compositionality would be to assess whether a new task can be more rapidly acquired if its components have been trained as part of other tasks previously.
(12) In Fig. 3 c and e, label the horizontal axis (cluster).
(13) It is great that the Tensorflow implementation will be shared. It would be good if the model data could also be shared in formats useful to people using Python as well as Matlab. This could be a great resource for students and researchers. Please state more completely in the main paper exactly what (Python code? Task and model code? Model data?) will be available where (Github?).
(14) After sequential training, performance at multisensory delayed decision making does not appear to suffer compared to interleaved training. Was this because multisensory delayed decision making was always the last task (thus not overwritten) or is it more robust because it shares more components with other tasks?
(15) A better word for “linear summation” is “sum”.
