An open review of Gorgolewski & Poldrack (PP2016)

The four pillars of open science are open data, open code, open papers (open access), and open reviews (open evaluation). A practical guide to the first three of these is provided by Gorgolewski & Poldrack (PP2016). In this open review, I suggest a major revision in which the authors add treatment of the essential fourth pillar: open review. Image: The Porch of the Caryatids (Porch of the Maidens) of the ancient Greek temple Erechtheion on the north side of the Acropolis of Athens.
Open science is a major buzz word. Is all the talk about it just hype? Or is there a substantial vision that has a chance of becoming a reality? Many of us feel that science can be made more efficient, more reliable, and more creative through a more open flow of information within the scientific community and beyond. The internet provides the technological basis for implementing open science. However, making real progress with this positive vision requires us to reinvent much of our culture and technology. We should not expect this to be easy or quick. It might take a decade or two. However, the arguments for openness are compelling and open science will prevail eventually.
The major barriers to progress are not technological, but psychological, cultural, and political: individual habits, institutional inertia, unhealthy incentives, and vested interests. The biggest challenge is the fact that the present way of doing science does work (albeit suboptimally) and our vision for open science has not merely not yet been implemented, but has yet to be fully conceived. We will need to find ways to gradually evolve our individual workflows and our scientific culture.
Gorgolewski & Poldrack (PP2016) offer a brief practical guide to open science for researchers in brain imaging. I was expecting a commentary reiterating the arguments for open science most of us have heard before. However, the paper instead makes good on its promise to provide a practical guide for brain imaging and it contains many pointers that I will share with my lab and likely refer to in the future.
The paper discusses open data, open code, and open publications – describing tools and standards that can help make science more transparent and efficient. My main criticism is that it leaves out what I think of as a fourth essential pillar of open science: open peer review. Below I first summarise some of the main points and pointers to resources that I took from the paper. Along the way, I add some further points overlooked in the paper that I feel deserve consideration. In the final section, I address the fourth pillar: open review. In the spirit of a practical guide, I suggest what each of us can easily do now to help open up the review process.
1 Open data
- Open-data papers more cited, more correct: If data for a paper are published, the community can reanalyse the data to confirm results and to address additional questions. Papers with open data are cited more (Piwowar et al. 2007, Piwowar & Vision 2013) and tend to make more correct use of statistics (Wicherts et al. 2011).
- Participant consent: Deidentified data can be freely shared without consent from the participants in the US. However, rules differ in other countries. Ideally, participants should consent to their data being shared. Template text for consent forms is offered by the authors.
- Data description: The Brain Imaging Data Structure (BIDS) (Gorgolewski et al. 2015) provides a standard (evolved from the authors’ OpenfMRI project; Poldrack et al. 2013) for file naming and folder organisation, using file formats such as NifTI, TSV and JSON.
- Field-specific brain-imaging data repositories: Two repositories accept brain imaging data from any researcher: FCP/INDI (for resting state fMRI only) and OpenfMRI (for any datasets that includes MRI data).
- Field-general repositories: Field-specific repositories like those mentioned help standardise sharing for particular types of data. If the formats offered are not appropriate for the data to be shared, field-general repositories, including FigShare, Dryad, or DataVerse can be used.
- Data papers: A data paper is a paper that focusses on the description of a particular data set that is publicly accessible. This helps create incentives for ambitious data acquisitions and to enable researchers to specialise in data acquisition. Journals publishing data papers include: Scientific Data, Gigascience, Data in Brief, F1000Research, Neuroinformatics, and Frontiers in Neuroscience.
- Processed-data sharing: It can be useful to share intermediate or final results of data analysis. With the initial (and often somewhat more standardised) steps of data processing out of the way, processed data are often much smaller in volume and more immediately amenable to further analyses by others. Statistical brain-imaging maps can be shared via the authors’ NeuroVault.org website.
2 Open code
- Code sharing for transparency and reuse: Data-analysis details are complex in brain imaging, often specific to a particular study, and seldom fully defined in the methods section. Sharing code is the only realistic way of fully defining how the data have been analysed and enabling others to check the correctness of the code and effects of adjustments. In addition, the code can be used as a starting point for the development of further analyses.
- Your code is good enough to share: A barrier to sharing is the perception among authors that their code might not be good enough. It might be incompletely documented, suboptimal, or even contain errors. Until the field finds ways to incentivise greater investment in code development and documentation for sharing, it is important to lower the barriers to sharing. Sharing imperfect code is preferable to not sharing code (Barnes 2010).
- Sharing does not imply provision of user support: Sharing one’s code does not imply that one will be available to provide support to users. Websites like org can help users ask and answer questions independently (or with only occasional involvement) of the authors.
- Version Control System (VCS) essential to code sharing: VCS software enables maintenance of complex code bases with multiple programmers and versions, including the ability to merge independent developments, revert to previous versions when a change causes errors, and to share code among collaborators or publicly. An excellent, freely accessible, widely used, web-based VCS platform is com, introduced in Blischak et al. (2016).
- Literate programming combines code and results and text narrative: Scripted automatic analyses have the advantage of automaticity and reproducibility (Cusack et al. 2014), compared to point-and-click analysis in an application with a graphical user interface. However, the latter enables more interactive interrogation of the data. Literate programming (Knuth 1992) attempts to make coding more interactive and provides a full and integrated record of the code, results, and text explanations. This provides a fully computationally transparent presentation of results, makes the code accessible to oneself later in time, and to collaborators and third parties, with whom literate programs can be shared (e.g. via GitHub). Software supporting this includes: Jupyter (for R, Python and Julia), R Markdown (for R) and matlabweb (for MATLAB).
3 Open papers
- Open notebook science: Open science is about enhancing the bandwidth and reducing the latency in our communication network. This means sharing more and at earlier stages, not only our data and code, but ultimately also our day-to-day incremental progress. This is called open notebook science and has been explored, by Cameron Neylon and Michael Nielson among others. Gorgolewski & Poldrack don’t comment on this beautiful vision for an entirely different workflow and culture at all. Perhaps open notebook science is too far in the future? However, some are already practicing it. Surely, we should start exploring it in theory and considering what aspects of open notebook science we can integrate into our workflow. It would be great to have some pointers to practices and tools that help us move in this direction.
- The scientific paper remains a critical component of scientific communication: Data and code sharing are essential, but will not replace communication through permanently citable scientific papers that link (increasingly accessible) data through analyses to novel insights and relate these insights to the literature.
- Papers should simultaneously achieve clarity and transparency: The conceptual clarity of the argument leading to an insight is often at a tension with the transparency of all the methodological details. Ideally, a paper will achieve both clarity and transparency, providing multiple levels of description: a main narrative that abstracts from the details, more detailed descriptions in the methods section, additional detail in the supplementary information, and full detail in the links to the open data and code, which together enable exact reproduction of the results in the figures. This is an ideal to aspire to. I wonder if any paper in our field has fully achieved it. If there is one, it should surely be cited.
- Open access: Papers need to be openly accessible, so their insights can have the greatest positive impact on science and society. This is really a no brainer. The internet has greatly lowered the cost of publication, but the publishing industry has found ways to charge higher prices through a combination of paywalls and unreasonable open-access charges. I would add that every journal contains unique content, so the publishing industry runs hundreds of thousands of little monopolies – safe from competition. Many funding bodies require that studies they funded be published with open access. We need political initiatives that simply require all publicly funded research to be publicly accessible. In addition, we need publicly funded publication platforms that provide cost-effective alternatives to private publishing companies for editorial boards that run journals. Many journals are currently run by scientists whose salaries are funded by academic institutions and the public, but whose editorial work contributes to the profits of private publishers. In historical retrospect, future generations will marvel at the genius of an industry that managed for decades to employ a community without payment, take the fruits of their labour, and sell them back to that very community at exorbitant prices – or perhaps they will just note the idiocy of that community for playing along with this racket.
- Preprint servers provide open access for free: Preprint servers like bioRxiv and arXiv host papers before and after peer review. Publishing each paper on a preprint server ensures immediate and permanent open access.
- Preprints have digital object identifiers (DOIs) and are citable: Unlike blog posts and other more fleeting forms of publication, preprints can thus be cited with assurance of permanent accessibility. In my lab, we cite preprints we believe to be of high quality even before peer review.
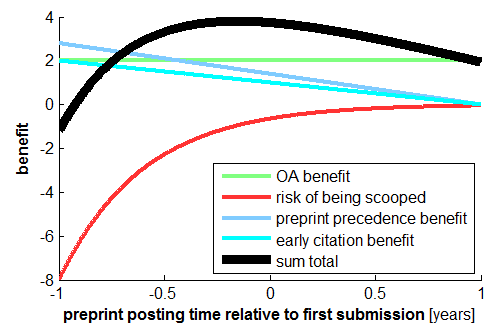
- Preprint posting enables community feedback and can help establish precedence: If a paper is accessible before it is finalised the community can respond to it and help catch errors and improve the final version. In addition, it can help the authors establish the precedence of their work. I would add that this potential advantage will be weighed against the risk of getting scooped by a competitor who benefits from the preprint and is first to publish a peer-reviewed journal version. Incentives are shifting and will encourage earlier and earlier posting. In my lab, we typically post at the time of initial submission. At this point getting scooped is unlikely, and the benefits of getting earlier feedback, catching errors, and bringing the work to the attention of the community outweighs any risks of early posting.
- Almost all journals support the posting of preprints: Although this is not widely known in the brain imaging and neuroscience communities, almost all major journals (including Nature, Science, Nature Neuroscience and most others) have preprint policies supportive of posting preprints. Gorgolewski & Poldrack note that they “are not aware of any neuroscience journals that do not allow authors to deposit preprints before submission, although some journals such as Neuron and Current Biology consider each submission independently and thus one should contact the editor prior to submission.” I would add that this reflects the fact that preprints are also advantageous to journals: They help catch errors and get the reception process and citation of the paper going earlier, boosting citations in the two-year window that matters for a journal’s impact factor.
4 Open reviews
The fourth pillar of open science is the open evaluation (OE, i.e. open peer review and rating) of scientific papers. This pillar is entirely overlooked in the present version of the Gorgolewski & Poldrack’s commentary. However, peer review is an essential component of communication in science. Peer review is the process by which we prioritise the literature, guiding each field’s attention, and steering scientific progress. Like other components of science, peer review is currently compromised by a lack of transparency, by inefficiency of information flow, and by unhealthy incentives. The movement for opening the peer review process is growing.
In traditional peer review, we judge anonymously, making inherently subjective decisions that decide about the publication of our competitors’ work, under a cloak of secrecy and without ever having to answer for our judgments. It is easy to see that this does not provide ideal incentives for objectivity and constructive criticism. We’ve inherited secret peer review from the pre-internet age (when perhaps it made sense). Now we need to overcome this dysfunctional system. However, we’ve grown used to it and may be somewhat comfortable with it.
Transparent review means (1) that reviews are public communications and (2) that many of them are signed by their authors. Anonymous reviewing must remain an option, to enable scientists to avoid social consequences of negative judgments in certain scenarios. However, if our judgment is sound and constructively communicated, we should be able to stand by it. Just like in other domains, transparency is the antidote to corruption. Self-serving arguments won’t fly in open reviewing, and even less so when the review is signed. Signing adds weight to a review. The reviewer’s reputation is on the line, creating a strong incentive to be objective, to avoid any impression of self-serving judgment, and to attempt to be on the right side of history in one’s judgment of another scientist’s work. Signing also enables the reviewer to take credit for the hard work of reviewing.
The arguments for OE and a synopsis of 18 visions for how OE might be implemented are given in Kriegeskorte, Walther & Deca (2012). As for other components of open science, the primary obstacles to more open practices are not technological, but psychological, cultural, and political. Important journals like eLife and those of the PLoS family are experimenting with steps toward opening the review process. New journals including, the Winnower, ScienceOpen, and F1000 Research already rely on postpublication peer review.
We don’t have to wait for journals to lead us. We have all the tools to reinvent the culture of peer review. The question is whether we can handle the challenges this poses. Here, in the spirit of Gorgolewki & Poldrack’s practical guide, are some ways that we can make progress toward OE now by doing things a little differently.
- Sign peer reviews you author: Signing our reviews is a major step out of the dark ages of peer review. It’s easier said than done. How can we be as critical as we sometimes have to be and stand by our judgment? We can focus first on the strengths of a paper, then communicate all our critical arguments in a constructive manner. Some people feel that we must sign either all or none of our reviews. I think that position is unwise. It discourages beginning to sign and thus de facto cements the status quo. In addition, there are cases where the option to remain anonymous is needed, and as long as this option exists we cannot enforce signing anyway. What we can do is take anonymous comments with a grain of salt and give greater credence to signed reviews. It is better to sign sometimes than never. When I started to sign my reviews, I initially reserved the right to anonymity for myself. After all this was a unilateral act of openness; most of my peers do not sign their reviews. However, after a while, I decided to sign all of my reviews, including negative ones.
- Openly review papers that have preprints: When we read important papers as preprints, let’s consider reviewing them openly. This can simultaneously serve our own and our collective thought process: an open notebook distilling the meaning of a paper, why its claims might or might not be reliable, how it relates to the literature, and what future steps it suggests. I use a blog. Alternatively or additionally, we can use PubMed Commons or PubPeer.
- Make the reviews you write for journals open: When we are invited to do a review, we can check if the paper has been posted as a preprint. If not, we can contact the authors, asking them to consider posting. At the time of initial submission, the benefits tend to outweigh the risks of posting, so many authors will be open to this. Preprint posting is essential to open review. If a preprint is available, we can openly review it immediately and make the same review available to the journal to contribute to their decision process.
- Reinvent peer review: What is an open review? For example, what is this thing you’re reading? A blog post? A peer review? Open notes on the essential points I would like to remember from the paper with my own ideas interwoven? All of the above. Ideally, an open review helps the reviewer, the authors, and the community think – by explaining the meaning of a paper in the context of the literature, judging the reliability of its claims, and suggesting future improvements. As we begin to review openly, we are reinventing peer review and the evaluation of scientific papers.
- Invent peer rating: Eventually we will need quantitative measures evaluating papers. These should not be based on buzz and usage statistics, but reflect the careful judgement of peers who are experts in the field, have considered the paper in detail, and ideally stand by their judgment. Quantitative judgments can be captured in ratings. Multidimensional peer ratings can be used to build a plurality of paper evaluation functions (Kriegeskorte 2012) that prioritise the literature from different perspectives. We need to invent suitable rating systems. For primary research papers, I use single-digit ratings on multiple scales including reliability, importance, and novelty, using capital letters to indicate the scale in the following format: [R7I5].
Errors are normal
As we open our science and share more of it with the community, we run the risk of revealing more of our errors. From an idealistic perspective that’s a good thing, enabling us learn more efficiently as individuals and as a community. However, in the current game of high-impact biomedical science there is an implicit pretense that major errors are unlikely. This is the reason why, in the rare case that a major error is revealed despite our lack of transparent practices, the current culture requires that everyone act surprised and the author be humiliated. Open science will teach us to drop these pretenses. We need to learn to own our mistakes (Marder 2015) and to be protective of others when errors are revealed. Opening science is an exciting creative challenge at many levels. It’s about reinventing our culture to optimise our collective cognitive process. What could be more important or glamorous?
Additional suggestions for improvements in revision
- A major relevant development regarding open science in the brain imaging community is the OHBM’s Committee on Best Practices in Data Analysis and Sharing (COBIDAS), of which author Russ Poldrack and I are members. COBIDAS is attempting to define recommended practices for the neuroimaging community and has begun a broad dialogue with the community of researchers (see weblink above). It would be good to explain how COBIDAS fits in with the other developments.
- About a third of the cited papers are by the authors. This illustrates their substantial contribution and expertise in this field. I found all these papers worthy of citation in this context. However, I wonder if other groups that have made important contributions to this field should be more broadly cited. I haven’t followed this literature closely enough to give specific suggestions, but perhaps it’s worth considering whether references should be added to important work by others.
- As for the papers, the authors are directly involved in most of the cited web resources OpenfMRI, NeuroVault, NeuroStars.org. This is absolutely wonderful, and it might just be that there is not much else out there. Perhaps readers of this open review can leave pointers in the comments in case they are aware of other relevant resources. I would share these with the authors, so they can consider whether to include them in revision.
- Can the practical pointers be distilled into a table or figure that summarises the essentials? This would be a useful thing to print out and post next to our screens.
- “more than fair” -> “only fair”
Disclosures
I have the following relationships with the authors.
| relationship |
number of authors |
| acquainted |
2 |
| collaborated on committee |
1 |
| collaborated on scientific project |
0 |
References
Barnes N (2010) Publish your computer code: it is good enough. Nature. 467: 753. doi: 10.1038/467753a
Blischak JD, Davenport ER, Wilson G. (2016) A Quick Introduction to Version Control with Git and GitHub. PLoS Comput Biol. 12: e1004668. doi: 10.1371/journal.pcbi.1004668
Cusack R, Vicente-Grabovetsky A, Mitchell DJ, Wild CJ, Auer T, Linke AC, et al. (2014) Automatic analysis (aa): efficient neuroimaging workflows and parallel processing using Matlab and XML. Front Neuroinform. 2014;8: 90. doi: 10.3389/fninf.2014.00090
Gorgolewski KJ, Auer T, Calhoun VD, Cameron Craddock R, Das S, Duff EP, et al. (2015) The Brain Imaging Data Structure: a standard for organizing and describing outputs of neuroimaging experiments [Internet]. bioRxiv. 2015. p. 034561. doi: 10.1101/034561
Gorgolewski KJ, Varoquaux G, Rivera G, Schwarz Y, Ghosh SS, Maumet C, et al. (2015) NeuroVault.org: a webbased repository for collecting and sharing unthresholded statistical maps of the human brain. Front Neuroinform. Frontiers. 9. doi: 10.3389/fninf.2015.00008
Knuth DE (1992) Literate programming. CSLI Lecture Notes, Stanford, CA: Center for the Study of Language and Information (CSLI).
Kriegeskorte N, Walther A, Deca D (2012) An emerging consensus for open evaluation: 18 visions for the future of scientific publishing Front. Comput. Neurosci http://dx.doi.org/10.3389/fncom.2012.00094
Kriegeskorte N (2012) Open evaluation: a vision for entirely transparent post-publication peer review and rating for science. Front. Comput. Neurosci., 17 http://dx.doi.org/10.3389/fncom.2012.00079
Marder E (2015) Living Science: Owning your mistakes DOI: http://dx.doi.org/10.7554/eLife.11628 eLife 2015;4:e11628
Piwowar HA, Day RS, Fridsma DB (2007) Sharing detailed research data is associated with increased citation rate. PLoS One. 2007;2: e308. doi: 10.1371/journal.pone.0000308
Piwowar HA, Vision TJ (2013) Data reuse and the open data citation advantage. PeerJ. 1: e175. doi: 10.7717/peerj.175
Poldrack RA, Barch DM, Mitchell JP, Wager TD, Wagner AD, Devlin JT, et al. (2013) Toward open sharing of taskbased fMRI data: the OpenfMRI project. Front Neuroinform. 2013;7: 1–12. doi: 10.3389/fninf.2013.00012
Wicherts JM, Bakker M, Molenaar D (2011) Willingness to Share Research Data Is Related to the Strength of the Evidence and the Quality of Reporting of Statistical Results. Tractenberg RE, editor. PLoS One. 6: e26828. doi: 10.1371/journal.pone.0026828