[I7R7]
An elegant new study by Bracci, Kalfas & Op de Beeck (pp2018) suggests that the prominent division between animate and inanimate things in the human ventral stream’s representational space is based on a superficial analysis of visual appearance, rather than on a deeper analysis of whether the thing before us is a living thing or a lifeless object.
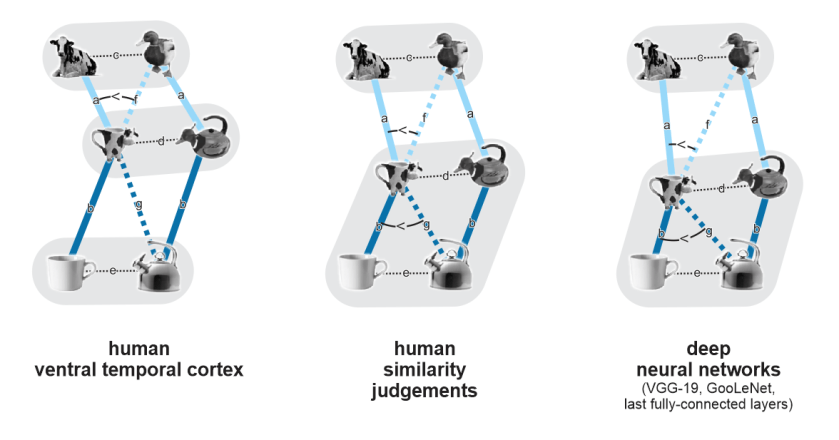
Bracci et al. assembled a beautiful set of stimuli divided into 9 equivalent triads (Figure 1). Each triad consists of an animal, a manmade object, and a kind of hybrid of the two: an artefact of the same category and function as the object, designed to resemble the animal in the triad.

Bracci et al. measured response patterns to each of the 27 stimuli (stimulus duration: 1.5 s) using functional magnetic resonance imaging (fMRI) with blood-oxygen-level-dependent (BOLD) contrast and voxels of 3-mm width in each dimension. Sixteen subjects viewed the images in the scanner while performing each of two tasks: categorizing the images as depicting something that looks like an animal or not (task 1) and categorizing the images as depicting a real living animal or a lifeless artefact (task 2).
The authors performed representational similarity analysis, computing representational dissimilarity matrices (RDMs) using the correlation distance (1 – Pearson correlation between spatial response patterns). They averaged representational dissimilarities of the same kind (e.g. between the animal and the corresponding hybrid) across the 9 triads. To compare different kinds of representational distance, they used ANOVAs and t tests to perform inference (treating the subject variable as a random effect). They also studied the representations of the stimuli in the last fully connected layers of two deep neural networks (DNNs; VGG-19, GoogLeNet) trained to classify objects, and in human similarity judgments. For the DNNs and human judgements, they used stimulus bootstrapping (treating the stimulus variable as a random effect) to perform inference.
Results of a series of well-motivated analyses are summarized in Figure 2 below (not in the paper). The most striking finding is that while human judgments and DNN last-layer representations are dominated by the living/nonliving distinction, human ventral temporal cortex (VTC) appears to care more about appearance: the hybrid animal-lookalike objects, despite being lifeless artefacts, fall closer to the animals than to the objects. In addition, the authors find:
- Clusters of animals, hybrids, and objects: In VTC, animals, hybrids, and objects form significantly distinct clusters (average within-cluster dissimilarity < average between-cluster dissimilarity for all three pairs of categories). In DNNs and behavioral judgments, by contrast, the hybrids and the objects do not form significantly distinct clusters (but animals form a separate cluster from hybrids and from objects).
- Matching of animals to corresponding hybrids: In VTC, the distance between a hybrid animal-lookalike and the corresponding animal is significantly smaller than that between a hydrid animal-lookalike and a non-matching animal. This indicates that VTC discriminates the animals and animal-lookalikes and (at least to some extent) matches the lookalikes to the correct animals. This effect was also present in the similarity judgments and DNNs. However, the latter two similarly matched the hybrids up with their corresponding objects, which was not a significant effect in VTC.
The effect of the categorization task on the VTC representation was subtle or absent, consistent with other recent studies (cf. Nastase et al. 2017, open review). The representation appears to be mostly stimulus driven.
The results of Bracci et al. are consistent with the idea that the ventral stream transforms images into a semantic representation by computing features that are grounded in visual appearance, but correlated with categories (Jozwik et al. 2015). VTC might be 5-10 nonlinear transformations removed from the image. While it may emphasize visual features that help with categorization, it might not be the stage where all the evidence is put together for our final assessment of what we’re looking at. VTC, thus, is fooled by these fun artefacts, and that might be what makes them so charming.
Although this interpretation is plausible enough and straightforward, I am left with some lingering thoughts to the contrary.
What if things were the other way round? Instead of DNNs judging correctly where VTC is fooled, what if VTC had a special ability that the DNNs lack: to see the analogy between the cow and the cow-mug, to map the mug onto the cow? The “visual appearance” interpretation is based on the deceptively obvious assumption that the cow-mug (for example) “looks like” a cow. One might, equally compellingly, argue that it looks like a mug: it’s glossy, it’s conical, it has a handle. VTC, then, does not fail to see the difference between the fake animal and the real animal (in fact these categories do cluster in VTC). Rather it succeeds at making the analogy, at mapping that handle onto the tail of a cow, which is perhaps an example of a cognitive feat beyond current AI.
Bracci et al.’s results are thought-provoking and the study looks set to inspire computational and empirical follow-up research that links vision to cognition and brain representations to deep neural network models.
Strengths
- addresses an important question
- elegant design with beautiful stimulus set
- well-motivated and comprehensive analyses
- interesting and thought-provoking results
- two categorization tasks, promoting either the living/nonliving or the animal-appearance/non-animal appearance division
- behavioral similarity judgment data
- information-based searchlight mapping, providing a broader view of the effects
- new data set to be shared with the community
Weaknesses
- representational geometry analyses, though reasonable, are suboptimal
- no detailed analyses of DNN representations (only the last fully connected layers shown, which are not expected to best model the ventral stream) or the degree to which they can explain the VTC representation
- only three ROIs (V1, posterior VTC, anterior VTC)
- correlation distance used to measure representational distances (making it difficult to assess which individual representational distances are significantly different from zero, which appears important here)
Suggestions for improvement
The analyses are effective and support most of the claims made. However, to push this study from good to excellent, I suggest the following improvements.
Major points
Improved representational-geometry analysis
The key representational dissimilarities needed to address the questions of this study are labeled a-g in Figure 2. It would be great to see these seven quantities estimated, tested for deviation from 0, and all 7 choose 2 = 21 pairwise comparisons tested. This would address which distinctions are significant and enable addressing all the questions with a consistent approach, rather than combining many qualitatively different statistics (including clustering index, identity index, and model RDM correlation).
With the correlation distance, this would require a split-data RDM approach, consistent with the present approach, but using the repeated response measurements to the same stimulus to estimate and remove the positive bias of the correlation-distance estimates. However, a better approach would be to use a crossvalidated distance estimator (more details below).
Multidimensional scaling (MDS) to visualize representational geometries
This study has 27 unique stimuli, a number well suited for visualization of the representational geometries by MDS. To appreciate the differences between the triads (each of which has unique features), it would be great to see an MDS of all 27 objects and perhaps also MDS arrangements of subsets, e.g. each triad or pairs of triads (so as to reduce distortions due to dimensionality reduction).
Most importantly, the key representational dissimilarities a-g can be visualized in a single MDS as shown in Figure 2 above, using two triads to illustrate the triad-averaged representational geometry (showing average within- and between-triad distances among the three types of object). The MDS could use 2 or 3 dimensions, depending on which variant better visually conveys the actual dissimilarity estimates.
Crossvalidated distance estimators
The correlation distance is not an ideal dissimilarity measure because a large correlation distance does not indicate that two stimuli are distinctly represented. If a region does not respond to either stimulus, for example, the correlation of the two patterns (due to noise) will be close to 0 and the correlation distance will be close to 1, a high value that can be mistaken as indicating a decodable stimulus pair.
Crossvalidated distances such as the linear-discriminant t value (LD-t; Kriegeskorte et al. 2007, Nili et al. 2014) or the crossnobis distance (also known as the linear discriminant contrast, LDC; Walther et al. 2016) would be preferable. Like decoding accuracy, they use crossvalidation to remove bias (due to overfitting) and indicate that the two stimuli are distinctly encoded. Unlike decoding accuracy, they are continuous and nonsaturating, which makes them more sensitive and a better way to characterize representational geometries.
Since the LD-t and the crossnobis distance estimators are symmetrically distributed about 0 under the null hypothesis (H0: response patterns drawn from the same distribution), it would be straightforward to test these distances (and averages over sets of them) for deviation from 0, treating subjects and/or stimuli as random effects, and using t tests, ANOVAs, or nonparametric alternatives. Comparing different dissimilarities or set-average dissimilarities is similarly straightforward.
Linear crossdecoding with generalization across triads
An additional analysis that would give complementary information is linear decoding of categorical divisions with generalization across stimuli. A good approach would be leave-one-triad-out linear classification of:
- living versus nonliving
- things that look like animals versus other things
- animal-lookalikes versus other things
- animals versus animal-lookalikes
- animals versus objects
- animal-lookalikes versus objects
This might work for devisions that do not show clustering (within dissimilarity < between dissimilarity), which would indicate linear separability in the absence of compact clusters.
For the living/nonliving destinction, for example, the linear discriminant would select responses that are not confounded by animal-like appearance (as most VTC responses seem to be), responses that distinguish living things from animal-lookalike objects. This analysis would provide a good test of the existence of such responses in VTC.
More layers of the two DNNs
To assess the hypothesis that VTC computes features that are more visual than semantic with DNNs, it would be useful to include an analysis of all the layers of each of the two DNNs, and to test whether weighted combinations of layers can explain the VTC representational geometry (cf. Khaligh-Razavi & Kriegeskorte 2014).
More ROIs
How do these effects look in V2, V4, LOC, FFA, EBA, and PPA?
Minor points
The use of the term “bias” in the abstract and main text is nonstandard and didn’t make sense to me. Bias only makes sense when we have some definition of what the absence of bias would mean. Similarly the use of “veridical” in the abstract doesn’t make sense. There is no norm against which to judge veridicality.
The polar plots are entirely unmotivated. There is no cyclic structure or even meaningful order to the the 9 triads.
“DNNs are very good, and even better than than human visual cortex, at identifying a cow-mug as being a mug — not a cow.” This is not a defensible claim for several reasons, each of which by itself suffices to invalidate this.
- fMRI does not reveal all the information in cortex.
- VTC is not all of visual cortex.
- VTC does cluster animals separately from animal-lookalikes and from objects.
- Linear readout of animacy (cross-validated across triads) might further reveal that the distinction is present (even if it is not dominant in the representational geometry.
Grammar, typos
“how an object looks like” -> ‘how an object looks” or “what an object looks like”
“as oppose to” -> “as opposed to”
“where observed” -> “were observed”
